개요
연결리스트 문제를 풀면서 모르는 점들이 많다고 느껴 해당 개념을 정리하고 관련 문제를 푸는 방법에 대해서 글을 작성하였습니다.
개념
연결리스트란?
배열 원소들의 순서를 유지하면서 임의의 위치에 원소를 삽입하거나, 임의의 위치에서 원소를 삭제하는 것은 시간이 오래 걸리는 작업입니다. 해당 위치 뒤에 있는 원소들을 하나씩 뒤칸 혹은 앞칸으로 옮겨야 하기 때문입니다. 평균적인 경우 이 작업들에는 원소의 개수에 선형 비례하는 시간이 걸립니다.
이와 같은 문제를 해결하기 위해 고안된 자료 구조가 연결 리스트(linked list)로, 특정 위치에서의 삽입과 삭제를 상수 시간에 할 수 있게 해줍니다. 연결 리스트는 배열과 아주 다른 형태를 가지고 있습니다.
- 배열에서는 메모리의 연속된 위치에 각 원소들이 저장되어 있다면,
연결 리스트는 원소들이 메모리 여기저기 흩어져 있습니다. - 연결 리스트는 각 원소들이 이전과 다음 원소를 가리키는 포인터를 가지고 있는 방식으로 구현됩니다
(정확하게는 이와 같은 연결 리스트를 양방향 연결 리스트라고 부르며, 이와 달리 각 원소가 다음 원소를 가리키는 포인터만 가지는 단방향 연결 리스트 또한 있습니다)

연결 리스트는 첫 번째 노드와 마지막 노드에 대한 포인터를 가지고 있는데, 이들을 각각 머리(head)와 꼬리(tail)라고 부릅니다. 대개 연결 리스트는 이와 같이 머리와 꼬리에 대한 포인터만을 가진 클래스로 구현됩니다.
연결 리스트 다루기
배열과는 달리 연결 리스트에서는 메모리 여기저기에 노드들이 흩어져 있기 때문에 특정 위치의 값을 찾기가 쉽지 않습니다. i번째 노드를 찾아내려면 리스트의 머리에서부터 시작해 하나씩 포인터를 따라가며 다음 노드를 찾을 수 밖에 없으며 결과적으로 i번째 노드를 찾는 데 드는 시간은 리스트의 길이에 선형 비례하게 됩니다.
반면 다른 노드들의 순서를 유지하면서 새 노드를 삽입하거나 기존 노드를 삭제하는 작업은 아주 간단합니다. 노드들의 순서가 포인터에 의해 정의되기 때문입니다. 다른 노드들은 그대로 두고, 삽입/삭제할 노드와 이전/이후 노드의 포인터만을 바꾸면 됩니다. 포인터만 변경하면 되기 때문에 연결 리스트에서의 삽입과 삭제는 각각 상수 시간에 이루어집니다.


문제풀이
문제 : 21. Merge Two Sorted Lists
정렬된 두 리스트를 오름차순으로 정렬된 하나의 리스트로 합치시오.
(https://leetcode.com/problems/merge-two-sorted-lists/)
풀이
개략적인 방법
본격적인 풀이에 앞서 연결 리스트 개념을 기억하면서 해당 문제를 그림으로 풀어보자

위 그림과 같이 두 개의 리스트가 주어졌을 때, 두 리스트의 head 중 더 작은 값을 가진 것은 L1 이다. 그래서 L1의 값을 임의의 리스트에 더해주고 L1의 포인터를 다음 노드로 옮겨 준다. 이 때 포인터를 옮기면서 이전 노드는 리스트에서 사라지므로 이를 회색박스로 blur 처리할 것이다.

이제 L1의 포인터가 현재 가리키고 있는 값인 5와 L2 포인터가 가리키고 있는 값인 3을 비교하여, 더 작은 값인 3을 임의의 리스트에 추가해준다. 마찬가지로 L2 리스트의 포인터를 다음 노드로 옮겨주고 이전 노드를 blur 처리한다.

L1, L2 둘 다 이미 정렬되어 있어서 두 리스트의 앞 부분만을 비교해서 임의의 리스트에 추가할 노드를 구할 수 있다. 이런식의 기법을 'Two pointers technique' 이라고 부른다. 해당 기법의 대표적인 응용 예제는 '두 개의 배열 합치기' 인데 '병합 정렬' 알고리즘의 한 부분이다. ( 추가적으로 병합 정렬의 수행시간은 O(NlogN) 이다 ). 두 개의 배열을 합치는 것에 대해서 알아보자.
두 배열 합치기
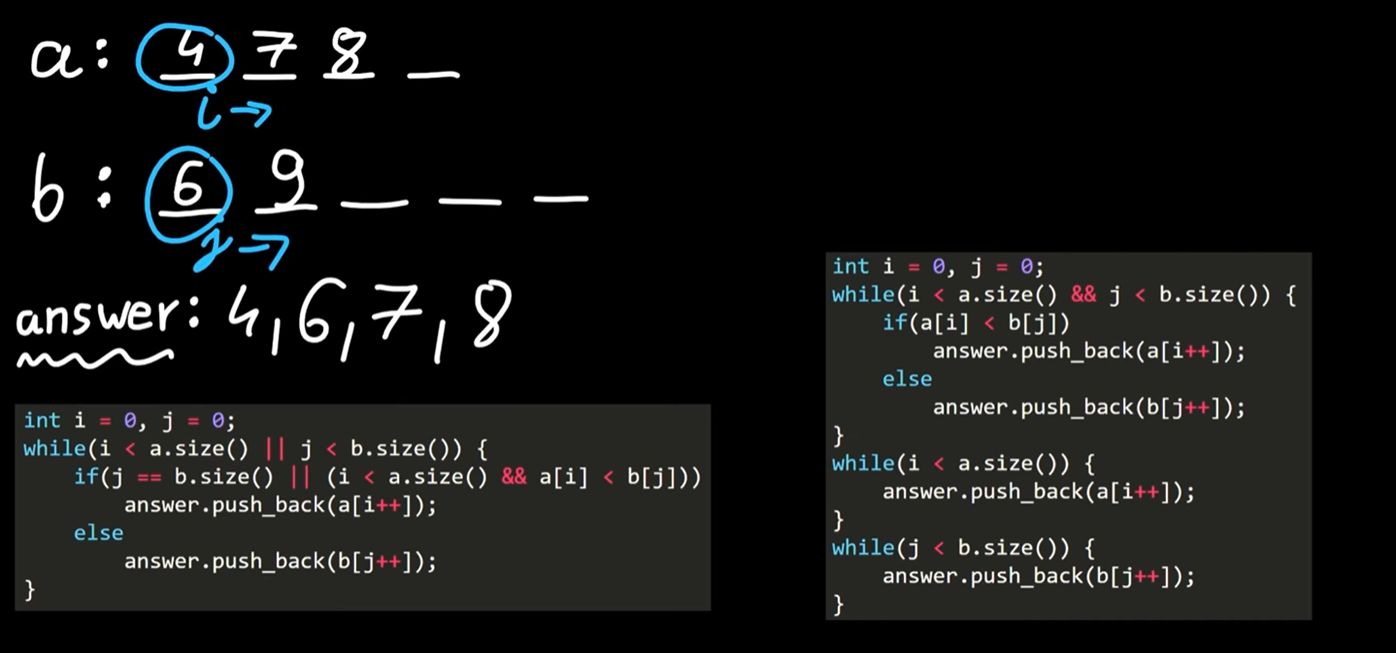
두개의 배열을 합치는 데는 크게 두 가지 방법이 있다. 첫 번째가 왼쪽 코드이고 두 번째가 오른쪽 코드이다. 둘은 각각 다르게 실행이 된다.
두 코드는 개략적으로 다음과 같이 동작한다.
a와 b라는 배열이 두 개 있고 각 배열의 인덱스를 각각 i, j 라고 하자. 두 인덱스는 배열의 0번째부터 시작한다.
그림처럼 a, b배열의 값을 각각 비교하여 더 작은 값을 answer 배열에 더해주고 더 작은 배열의 i 또는 j 인덱스를 1씩 증가시켜나간다. 이 작업을 배열의 크기만큼 반복한다.
왼쪽 코드

while 루프는 i 또는 j 인덱스가 배열의 크기를 벗어나지 않으면 계속 반복한다. 설령 i 인덱스가 먼저 배열의 크기를 벗어나도 j 인덱스가 배열 크기보다 작다면 계속 반복한다.
루프 내에 위치한 if 문은
- j 인덱스가 b 배열의 인덱스 범위를 벗어나거나
- 또는 (j 인덱스가 b 배열의 인덱스 범위 내에 있으며) i 인덱스가 a 배열의 인덱스 범위 내에 있고
- a배열 값이 b 배열 값보다 작으면
- a 배열 값을 answer 배열에 대입하고 i 인덱스를 증가시킨다.
- a배열 값이 b 배열 값보다 작으면
- 반대의 경우 (i 인덱스가 a 배열의 인덱스 범위를 넘어섰거나, a 배열 값이 b 배열 값보다 클 때)
- b 배열 값을 answer 배열에 대입하고 j 인덱스를 증가시킨다.
코드는 상대적으로 짧지만 제어문 처리가 복잡하다는 것을 느껴진다.
오른쪽 코드

while 루프는 i, j 인덱스 둘 다 배열의 크기를 벗어나지 않았으면 계속 반복한다.
루프 내에 위치한 if 문은
- a 배열 값과 b 배열 값 중 더 작은 값을 answer 배열에 대입한다.
루프가 끝난 뒤에는 배열에서 처리하지 못한 원소들이 남아있기 때문에 별개로 추가적인 while 루프를 진행한다.
- 예를 들어 a 배열의 크기가 3, b 배열의 크기 5라고 하자. 첫 번째 루프는 a 배열의 사이즈인 3만큼 반복하고 끝이 나므로 b 배열에 처리하지 못한 원소들이 2개 남아있다.
- 그러므로 별개의 루프로 원소들을 처리해줘야 한다. j 인덱스가 b 배열의 크기만큼 커질 때까지 반복하면서 원소를 answer 배열에 대입해준다.
비교
두 코드를 비교해보았을 때 왼쪽 코드가 좀 더 짧기 때문에 낫지 않나는 생각이 든다. 그렇다고 왼쪽 코드가 두 개의 배열을 합치는데 더 나은 성능을 보이는 것은 아니다. 두 코드 모두 두 개의 배열을 합치면서 새로운 배열을 추가로 만들기 때문에 공간 복잡도는 선형이고 이는 효율적이지 않다.
대신 이것은 배열들을 합쳤을 때 발생하는 문제이고, 우리는 연결 리스트 문제를 해결할 것이므로 리스트의 포인터만 수정해주면 추가적인 메모리를 소비하지 않고도 합칠 수 있다.
결론적으로 연결 리스트에게는 오른쪽 코드가 훨씬 더 나은 수행을 보인다. 왜 그런지 살펴보자,

둘 중의 하나의 연결 리스트를 이미 다 돌았다고 하자. 위 그림처럼 L1 리스트 포인터는 마지막 값인 8을 가리키다가 한번 더 이동하여 NULL을 가리킨다. ( 리스트 포인터가 이동하는 것을 코드로 나타내면 L1 = L1.next 이다 )
앞서 두 개의 배열을 합치는 부분을 상기하면 'L1은 이미 다 돌았고, 남은 L2 원소를 while 루프로 반복시켜서 처리하면 되겠네?' 라고 생각이 든다. 그러나 연결 리스트는 그럴 필요없이 그냥 L1의 포인터가 L2의 노드를 가리키게 하면 된다.

NULL을 가리키던 포인터가 이제 L2 의 9 를 가리킨다.
L2 의 값 12 다음에 수백개, 수천개의 노드가 남아있어도 일일이 루프로 반복해서 처리할 필요없다. 그냥 L1의 마지막 노드가 L2의 노드를 가리키게만 하면 된다. 포인터와 값은 알맞게 세팅되었으며 마지막으로 리스트를 반환하면 된다. 최종적으로 L1, L2 리스트가 합쳐지게 되면 다음과 같이 그려진다.

다시 코드로..
다시 코드로 돌아오자. 배열이 아닌 리스트로 구성할 경우
- 왼쪽 코드는 하나의 리스트의 크기만큼 반복해도 끝나지 않고 불필요하게 모든 리스트를 반복해서 처리하려 한다.
- 오른쪽 코드에선 두 개의 리스트 코드 중 하나가 끝나면 루프가 끝이 난다. 하단의 while 루프 작업들은 포인터를 바꿔주는 하나의 작업(ex. if 제어문)으로 대체해주면 된다.
그러므로 연결 리스트에서는 오른쪽 코드가 더 나은 성능을 보인다는 것이다. 그러나 아직 살펴볼 것들이 남아있다.
연결 리스트 처리 방식

위와 같은 형태의 리스트들이 주어져 있을 때 정답 리스트를 만들어 여기에 값을 오름차순으로 연결해줄 것이다.

먼저 맨 앞의 노드들을 비교한다. 이 경우 2가 3보다 작은 값이므로 2는 정답 리스트의 head가 된다. 그리고 L1 리스트의 그 다음 노드를 비교하기 위해 L1 포인터만 옮긴다.

L1 리스트에서 2 다음에는 5라는 값이 나오지만 전체 리스트의 입장에선 아직 어떤 값인지 모르기 때문에 비워놨다.
(유튜브에선 아직 모른다 라는 정도로 설명해서 정확하게 표현한 것인지 확실하지 않습니다..)
2는 전체 노드의 시작점(START)이 된다.
이 때 기억해야할 것은, 문제의 정답으로 리스트를 반환해야 하는데 리스트의 맨 처음을 가리키는 포인터는 HEAD 라고 했던 것을 기억하는가? 이 HEAD 포인터가 위의 그림에선 START 가 되고 우리는 START 포인터를 반환할 것이다. START 포인터는 리스트의 맨 처음을 가리키는 HEAD 포인터이다.
2에서 5를 가리키는 포인터는 이제 3을 가리킨다. 이제 L1의 5와 L2의 3을 비교했을 때 더 작은 값은 3이므로 L2 포인터를 이동시킨다.


L2의 다음노드를 비워놓은 것은 정답 리스트의 입장에선 다음 값이 무엇인지 모른다고 보기 때문에 비운 것이다.

이제 L1의 5와 L2의 4를 비교했을 때 L2값이 더 작으므로 L2 포인터를 또 이동시킨다. 지금까지의 정답리스트를 빨간색으로 칠하면 아래와 같다.

정답리스트는 현재 2->3->4 까지 연결되어 있다.
이 때 LAST 라고 정답 리스트의 마지막 노드를 가리키는 포인터에 이름을 붙였다. LAST 는 L1, L2 리스트를 비교하면서 둘 중 더 작은 값을 가리키는 포인터이다.
그래서 L1, L2 중 더 작은 값을 LAST가 가리키고 L1 또는 L2 포인터는 자신의 다음 노드로 이동을 한다. 이 작업을 while 루프가 끝날 때까지 반복한다.
만약 5와 5 처럼 같은 값에 대한 처리도 전혀 문제되지 않는다. 왜냐하면 그냥 가리키게만 하면 되기 때문이다.

위 그림에서 L1 포인터가 가리키는 5와 L2 포인터가 가리키는 5는 서로 같지만 전혀 동작에 문제되지 않는다. 우리 풀이에서는 이럴 때 L2 포인터를 이동시켜줄 것이다. 그럼 아래 그림과 같이 L2 포인터가 이동하면서 LAST 또한 이동된다.

리스트로 푸는 개념적인 설명은 여기까지이다. 혹시 이해가 안된다면 단계별로 천천히 읽어보도록 하자. 이제 직접 코드로 들어가서 코드를 최적화 하는 방법까지 알아볼 것이다.
코드

(자바스크립트로 작성해서 c의 포인터로 학습하신 분들은 조금 헷갈리실 수도 있습니다. 해당 풀이 저자는 c++ 로 문제를 풀었으므로 참고하실 분들은 글 하단 출처를 확인 해주시기 바랍니다)
(다만 자바스크립트로 작성했을 때 ListNode 자료 구조의 next 는 다음 노드를 가리키는 포인터이고, 이 후 나오는 fake, last 는 노드입니다)
(c++ 의 경우 last는 포인터로 선언됩니다)
start, last 포인터를 선언하고 L1, L2 중 더 작은 값을 start 가 가리키게 한다. 그리고 해당 리스트를 한칸 이동 시키며 마지막으로 last를 start 와 똑같은 값을 가리키도록 정의한다.
아직 메인 알고리즘에 들어가기 전 초기화 작업인데 이대로만 하면 L1과 L2가 빈 리스트 일 경우 문제가 발생한다. null의 val 을 가져오려고 하면 에러를 일으키므로 다음과 같이 처리해준다.

단순한 초기화 작업인데 코드가 불필요하게 길다. 이를 단순하게 할 수 있는 방법을 소개한다.
연결 리스트 문제를 풀 때는 항상 fake vertex, dummy vertex (비어있는 노드) 를 고려해본다.
다음 그림을 보자.

위 그림처럼 -1 값을 가진 fake 노드를 임의로 추가한다. 값은 100, 1000 등이 될 수도 있지만 상관없다. -1 또는 0 이 처음 시작이라는 의미가 있기 때문에 보통 해당 값을 사용한다.
아무튼 앞선 코드처럼 다량의 if문 대신, -1 값을 갖는 노드를 추가하자. 이를 START 노드라고 할 것이다. 그리고 while 루프를 돌면서 이 노드 다음에 더 작은 값들을 연결해줄 것이다.

위 그림처럼 노드들이 연결될 것이고 결과적으로 정답 리스트를 얻게 될 것이다. 한 개의 불필요한 노드를 추가함으로써 위와 같은 결과를 얻는다. ( 여기까지만 보면 큰 차이를 못 느낄 것이다. 그 차이는 코드에서 확 느낄 수 있다 )
그리고 정답으로 START의 next를 반환할 것이다. START는 정답 리스트의 맨 처음을 가리킨다는 것을 앞서 얘기한 적이 있다. START의 next는 정답 리스트의 첫 번째 노드인 2를 가리키므로, 2 이후에 연결된 노드들은 우리가 원하던 정답리스트다.
다시 코드로 돌아가보자.

그래섯 연결 리스트 문제를 풀 때는 언제나 항상 fake 노드를 만든다는 것을 기억하자.
코드에 fake 노드를 만들었고 이를 LAST에 초기화 해준다. fake 노드를 만들었기 때문에 START는 필요 없으므로 지운다. 코드들을 모두 지운 결과는 아래 그림과 같다.

엄청 간단해졌다. 이게 바로 fake 노드를 만듦으로 인해 얻는 이점이다. 이제 우리가 두개의 배열을 비교했을 때 사용한 코드를 상기시켜보면서 남은 로직을 완성시키자.

배열과 다른 점은 리스트이기 때문에, 범위 내인지에 대한 검사를 노드가 null 인지 확인하는 점이다.
루프 내 if 문에서
- L1 리스트 값과 L2 리스트의 값을 비교한다.
- 더 작은 값을 LAST 포인터가 가리키게 한다.
- 그리고 LAST 노드는 L1, L2 리스트의 노드 중 더 작은 노드가 된다.
- 이 후 L1 또는 L2 리스트의 포인터를 이동시키며 해당 작업을 반복한다.
예를 들면, L1의 5가 정답 리스트와 연결이 되어야 할 때
- LAST 포인터가 5를 가리키게끔 하고 (last_node.next = l1)
- 5는 LAST 노드가 되며 (last_node = l1)
- L1 리스트의 포인터를 이동시킨다. (l1 = l1.next)
이런 식으로 두 리스트를 비교하며 정답 리스트를 연결해나간다.
처리가 덜 된 리스트 노드가 남아있을 수 있으니 L1 또는 L2 리스트가 null 인지 비교하여 LAST 노드의 포인터에 덜 처리된 리스트를 연결해준다.
리스트이기 때문에 포인터만 연결해주도록 제어문을 작성해준다. 단순히 LAST 포인터가 L1 또는 L2 리스트의 노드를 가리키게만 하면 된다.
마지막으로 fake 노드의 next를 리턴한다.
fake 노드에는 -1 값이 있지만 우리는 이 값을 어디에도 사용하지 않았다. 그래서 -1 이든, 100을 주든 상관이 없는 것이다. fake의 next는 실제 정답 리스트의 첫 번째 노드를 가리킨다.
코드를 제출해보면 통과하는 것을 볼 수 있다.
소감
처음에는 이 문제를 잘 풀지 못하여 다른 사람의 풀이를 보고 이해를 하려했는데, 이 사람이 풀이 설명을 하는데 단계별로 상세하게 설명하지 않고 뭉텅거려서 넘어가서 제대로 이해가 안됐다. 어째서 temp 노드가 계속 변하는데 first 노드가 가리키는 것은 전체 정답 리스트를 가리킬 수 있을까? 라는 의문이 들었다. 항상 링크드 리스트는 그 순간만 이해하고 넘어갔던 경향이 있던 것 같고 매번 같은 포인트에서 헷갈리는 것 같아서 알고리즘 문제 해결 전략 책을 구입하기로 결심하고 이렇게 글로 정리했다.
이 풀이를 제시해준 유튜버가 가졌던 의문외에도 많은 부분들을 정말 명쾌하게 잘 설명해주어서 이것을 글로 옮겨야 겠다는 생각이 들었다. 약 3일? 5일 정도 이글을 작성하였는데 번역을 하는 게 어렵기도 했지만. ( 링크드 리스트다 보니 포인터가 어디를 가리킨다 는 표현을 to the, to.. 를 엄청 섞어서 쓰는데 제대로 이해하기 매우 헷갈렸다) 역시 개념을 잘 모르고 있기 때문에 설명하는 것도 이해하지 못한다는 생각도 들었다. 다른 것보다 자바스크립트는 c++ 와 달리 포인터 개념이 없어서 헷갈린 것도 큰 것 같다. 그림 설명을 작성하는데 어떤 것은 포인터고 어떤 것은 노드이고, 어떤 표현은 포인터로 가리킨다고 하고 어떤 것은 포인터가 된다고 하고..이런 것들을 통일성 있게 표현하는데 노력했다. 혹시나 링크드 리스트 개념에 어려움을 가지신 분들께 도움이 되었으면 좋겠다.
+ 혹시 글에서 잘못된 설명이나 그런 부분이 있는 경우 댓글로 꼭 피드백 해주시면 정말 감사하겠습니다 !!
출처
알고리즘 문제 해결 전략 2권 (구종만)
'Algorithm 개념 및 문제풀이 > Knowledge' 카테고리의 다른 글
| 동적 계획법 개념정리 (0) | 2020.04.06 |
|---|

댓글